AI Photography Reimagined: From Lens to Code
One Photoshoot, Infinite Possibilities: Generative AI in Fashion Imagery
“Redefine the creative process behind fashion photography”.
This project explored how generative AI can redefine the creative process behind fashion photography - transforming a single photoshoot into a dynamic, multi-dimensional content engine.
Using AI-driven tools, the goal was to decouple the limitations of traditional fashion imagery by altering garments, backgrounds, lighting, and even models - all from a single lens capture. This approach opens up a radically more flexible, sustainable, and emotionally responsive method of image-making.
By generating diverse, adaptive visual outputs, brands are now able to reduce costs, minimize environmental impact, and elevate creative agility - without sacrificing narrative power. But beyond efficiency, the project points toward something deeper: a future where fashion visuals are not just edited, but co-created with AI - blurring the lines between memory, identity, and design.
This vision is not about replacing human artistry - it’s about enhancing it. One photoshoot becomes an infinite canvas. One image becomes many stories.
The Process:
-
![]()
1. Photoshoot capture
Single lens image capture of the model wearing the garment
-
![]()
2. LoRa Style Application in Comfy UI
Custom-trained LoRa Models (romantic and baroque themes) applied to the base image to guide AI reinterpretation
-
![]()
3. Pose Detection+Image Segmentation
Pose estimated via IPAdapter + clothing mask identified for garment targeting
-
![]()
4. Animated or Multi-style Output
One model, multiple high-fashion outputs - rendered across shifting worlds, emotions, and aesthetics.

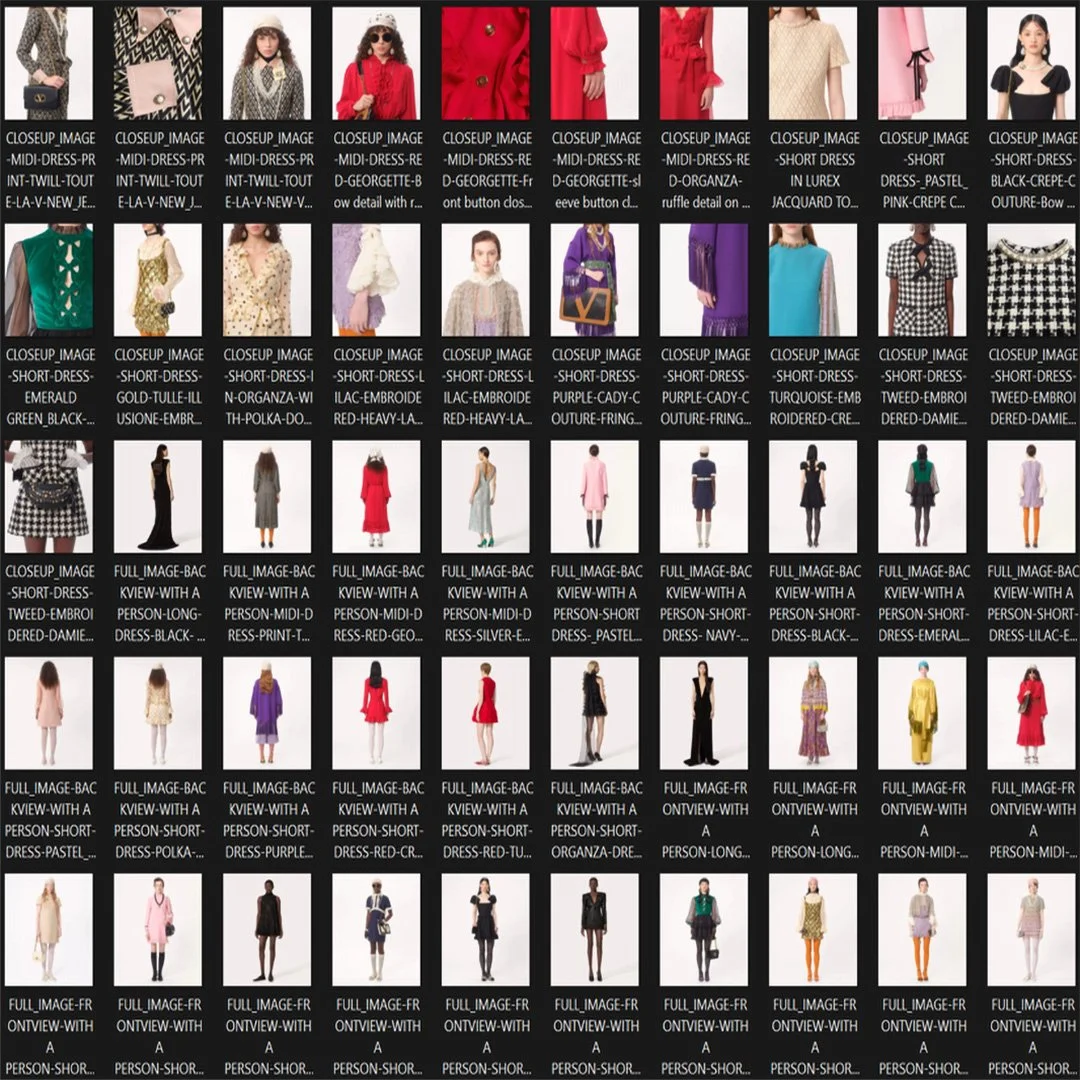


One Lens Many Lives
The Style Engine: Romantic + Baroque
Where Code Meets Couture
This is where code dreams in velvet. Where the folds of a ruffled sleeve echo cathedral ceilings, and each silhouette carries the ache of a love letter never sent. Inspired by Valentino and trained on romantic maximalism and the golden excess of baroque form, this LoRA engine renders gowns not as fashion, but as portals - each garment a memory, each detail a verse in an unspoken opera of beauty, power, and longing.
Moodboard















Co-created Garments:
Where code and human touch meet
Custom Trained LoRA’s:
Acted as style filters drawing on romantic and Baroque references and Valentino inspiration not just for colour or texture, but for mood and narrative.
Comfy UI - Workflow

Visual Pipeline: Virtual try-on using pose estimation, garment masking, and IPAdapter prompts in ComfyUI.
Virtual Try-on that is a ground-breaking diffusion model that enables virtual garment try-on. By preserving the unique details and identity of garments, IDM-VTON generates incredibly authentic and realistic results.
The model utilizes an image prompt adapter (IP-Adapter) to extract high-level garment semantics and a parallel UNet (Garment Net) to encode low-level features.
In Comfy UI, the IDM-VTON node powers the virtual try-on process, requiring inputs such as a human image, pose representation, clothing mask, and garment image as represented in the diagram on the left.
The Virtual Changing Room
Generative Imagery in Motion
One Look, Many Worlds
Closing Statement
This project marked a pivotal step in reimagining the fashion image not as a static capture, but as a living system - one that evolves through code, style memory, and digital interpretation. By fusing traditional photography with AI-led transformation, it offered a glimpse into a new visual future: one where fashion stories are no longer bound by location, repetition, or resource, but unfold infinitely through creativity and computation. What begins with one image becomes a constellation of identity, expression, and possibility.
Collaborations : Curious minds and creative collaborators are always welcome. Whether you’re into AI, animation, or storytelling through design—let’s connect and see what we can create together.
Contributors: Alex Marshall and Dan Adakpor, the content production team at London College of Fashion and Emy Cies, the model